
Stop Arguing About Your RAG. Your Retrieval Strategy Is Broken
A real-world RAG failure story, from chunk-size debates to fixing retrieval the hard way.

1. The Chunking Obsession
We spent weeks arguing about chunk size. Not because it was interesting, but because it was available. The retrieval wasn’t working. Users kept getting answers that were technically correct and somehow completely wrong. The kind of wrong that doesn’t break immediately, but quietly erodes trust after the second or third follow-up. So we did what engineers always do when something feels off. We looked for a number to change.
Chunk size felt safe. Too small and you lose context. Too big, and the embedding gets muddy. We changed it from 1024 to 512. Ran evals. Changed it again. Watched the metrics move just enough to convince ourselves we were making progress.
Then overlap entered the chat. What if chunks shared 50 tokens? What about 100? What if we tuned both at the same time? We built scripts. We generated charts. We had opinions about the charts. Slack threads got longer. Sprint notes started to include phrases like “continued chunking optimization.”
Meanwhile, users were still asking simple questions and getting stitched-together nonsense in return. The system couldn’t answer “What did the CEO say about hiring?” without pulling fragments from three different quarters and merging them into something that looked responsive but made no sense to anyone who had actually been there.
Chunking is comforting. It feels like engineering. You tweak a parameter, rerun an experiment, and get new numbers. You can debate it without questioning the system itself. You can stay busy without being uncomfortable.
Because questioning chunk size is easier than asking harder questions, are we even retrieving the right documents? Does our embedding model understand what “hiring” means in this company? Are we searching broadly when the question is narrow? Are we mixing relevance with convenience?
We never said it out loud, but everyone knew. Changing the chunk size felt like progress. Questioning retrieval felt like admitting we might have built the wrong thing.
So we changed the chunk size again.
2. Why Chunking Fails as a Primary Lever
The eval scores went up. We shipped it.
The complaints didn’t stop. They just changed shape. Instead of three completely random paragraphs, users now get two paragraphs from the same document. We called it progress. The dashboard agreed.
But when you sat next to a real user and watched them type a question, the problem was obvious. Someone would ask, “Did we commit to the new benefits policy?” and the system would return a chunk that mentioned benefits and policy, but not commitment or timing. Technically relevant. Practically useless.
We had optimized for a score that measured whether the right document appeared somewhere in the top results. We hit the target. We celebrated. What we never measured was whether the answer helped anyone decide anything.
Chunk boundaries weren’t the issue. They never were.
When we finally looked at what was actually being retrieved, the pattern was clear. Documents were ranked by semantic similarity, which sounds reasonable until you realize similarity and usefulness are not the same thing. A query about remote work would pull every document that mentioned remote work, regardless of whether it was current, authoritative, or even finalized.
We treated retrieval like a solved problem. Embed the query, search the vector space, return the closest chunks. Chunking was supposed to make the matches better. Better at what, we never asked. We assumed semantic closeness was the goal because that’s what the tools made easy.
The chunk size debates had served their purpose. They gave us something concrete to tune while avoiding a harder truth. We didn’t actually know what good retrieval looked like for our users. We knew what good metrics looked like. We knew how to move them.
Looking back, chunking was never the fix. It was the distraction. As long as we were adjusting parameters, we didn’t have to admit that we had built a system that returned documents, not answers, and called it success because the numbers were green.
We spent weeks tuning the chunk size. We should have spent hours asking what we were actually trying to retrieve, and why we thought closeness in vector space would get us there.
We didn’t ask that question. We shipped the better metrics and moved on.
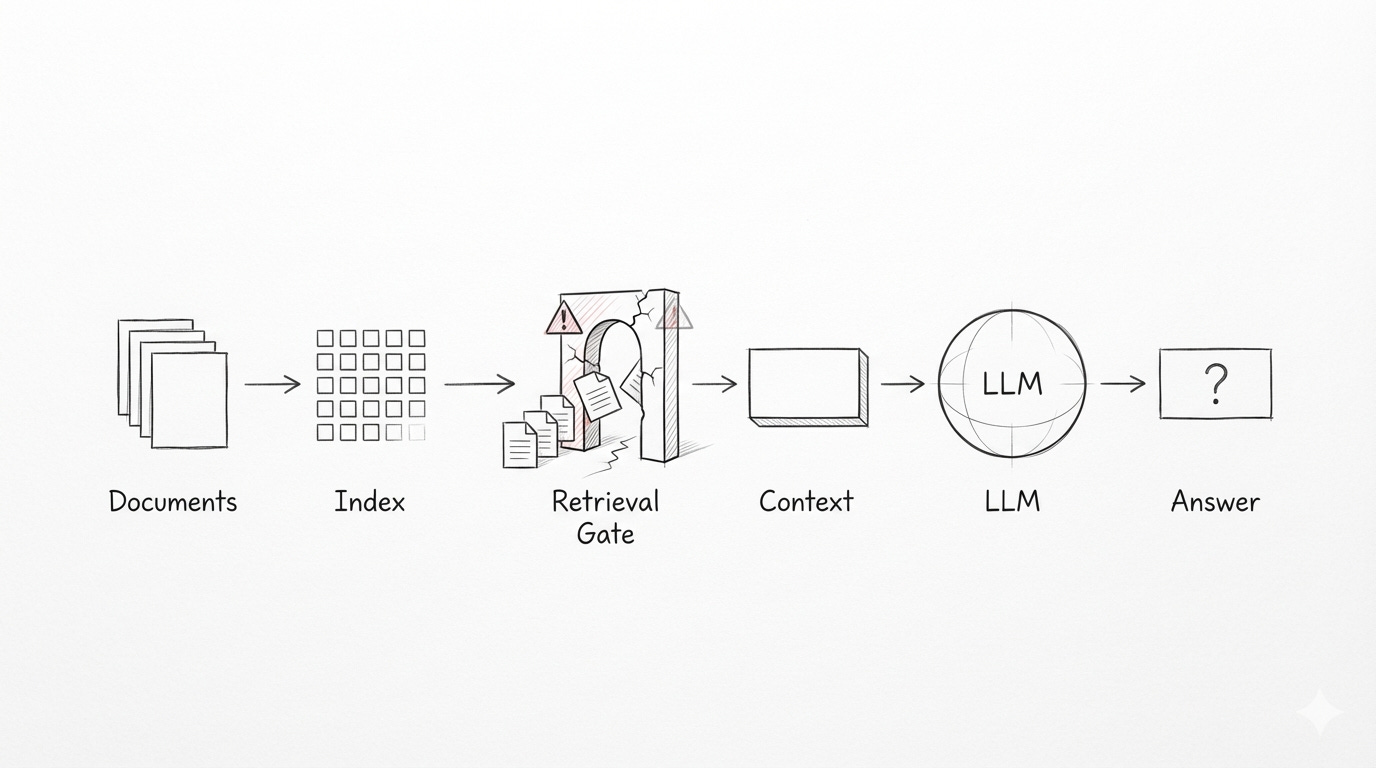
3. Retrieval Is the Real Architecture
The model only sees what you give it.
This sounds obvious until you watch a system fail in production. The failure rarely starts at the prompt or the model. It starts earlier, in the quiet decision about what context is even allowed to exist.
Retrieval defines the model’s world. It decides which documents count as evidence, which passages are worth considering, and which facts are silently excluded. Long before the LLM reasons about anything, retrieval has already constrained what reasoning is possible.
We often confuse storage with access. Documents sit in databases and file systems, and we assume that means the knowledge is available. It isn’t. Stored documents are inert. Knowledge only exists when the system can reliably surface the right information at the right moment, for the right question.
Retrieval narrows the reasoning space without announcing itself. If it fetches incomplete history, outdated context, or loosely related material, the model doesn’t fail. It does exactly what it should: it reasons over what it sees. The output looks coherent, sometimes even confident, but it is built on a distorted view of reality.
This is why so many RAG failures feel subtle. Nothing crashes. No errors are thrown. The system responds fluently, but the answers drift. They are relevant in tone, plausible in structure, and wrong in substance. The problem isn’t hallucination. The problem is that the evidence was never there.
Most production failures happen before the LLM ever runs. By the time the prompt is assembled, the outcome is already determined by retrieval. The model cannot reason about information it was never shown, and no amount of prompt tuning can compensate for missing or misleading context.
Retrieval is not a preprocessing step. It is not a component you “set up” and move on from. It is the architecture of the system. It governs access to knowledge, defines the boundaries of truth, and determines whether the model ever has a chance to be correct.
When RAG systems fail, it’s rarely because the model isn’t smart enough. It’s because retrieval never gave it a fair view of the problem.
4. What Actually Breaks Retrieval
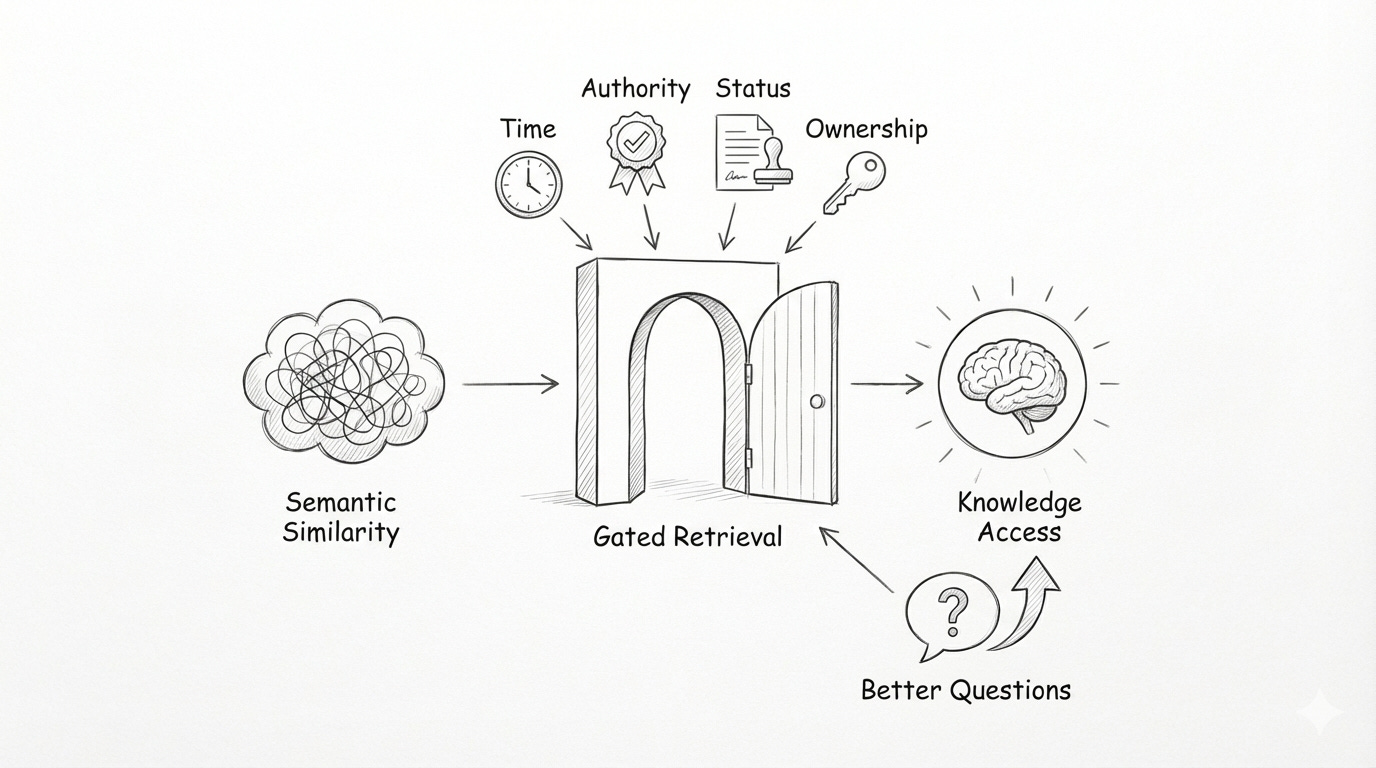
We ship embedding-only search and call it retrieval. It works just well enough to be dangerous. Semantic similarity pulls in content that feels related, but it quietly drops the signals that actually matter. Time. Authority. Document type. Status. Ownership. What comes back is a stack of documents that vaguely fit the question, while hiding the context that would make any of them trustworthy.
Then we make it worse by forcing a single similarity score to do all the work. One metric. One threshold. Every query treated the same. Generic documents float to the top because they match more broadly, while the precise, decision-bearing material sinks. The ranking becomes predictable in the wrong way, and we mistake that stability for correctness.
We also ignore intent and domain structure, even though they define relevance. The same words mean different things depending on whether someone is asking for a policy, a decision, a timeline, or an exception. A question about a CEO hiring comment is not the same as a question about a benefits effective date, yet both are pushed through the same scoring gate as if intent were irrelevant.
In production, this shows up fast. Ask for a roadmap commitment, and you get documents describing general product themes, not the specific timeline or owner. Ask about a policy exception, and the system returns a governance overview, not the actual carve-out. Each answer sounds reasonable. Each one misses the point.
The pattern repeats. The surface stays coherent while the structure underneath is wrong. Retrieval shapes what the model can see and, just as importantly, what it cannot. Once those signals are off, answer quality degrades before the model ever runs.
These are not prompt issues. They are not model failures. They are design failures in how access to knowledge is granted. Retrieval stops being an amplifier and becomes the constraint. And by the time the LLM speaks, the damage is already done.
5. Better Questions to Ask Instead
We kept asking how to make retrieval better. We should have been asking what retrieval is actually for. The real question isn’t “How do we find similar documents?” It’s “What does the model need to see to answer this question correctly?” Those are different problems. One is search. The other is access to knowledge.
That shift starts by deciding which signals should gate retrieval. Time matters. Is this the current policy or an outdated draft? Authority matters. Who signed this, and does their role give it weight? Status matters. Is this a proposal, a final decision, or an exception? Ownership matters. Who can confirm or override it? Without these signals, semantic similarity just produces content that feels related while quietly erasing trust.
Context is not about volume. It’s about the context that changes how an answer should be interpreted. When someone asks about a policy, they don’t need every document that mentions it. They need the final version, the effective date, and the authority behind it. When they ask about an exception, they need the rationale and the approval, not a generic overview. More text rarely adds clarity. It usually blurs it.
This is where precision starts to matter more than recall. In production systems, returning many “kind of relevant” results is often worse than returning one exact, authoritative answer. Timelines, commitments, and constraints don’t benefit from breadth. They benefit from specificity. Flooding the model with loosely related context forces it to average meaning instead of relying on evidence.
We’ve seen this play out repeatedly. A roadmap question returns broad product themes instead of a concrete commitment. A benefits timing question surfaces drafts instead of the effective policy. A policy exception query retrieves governance notes but not the actual carve-out. Each result is plausible. None of them are decisive.
At some point, the pattern becomes clear. Retrieval doesn’t fail because the system can’t find enough. It fails because it doesn’t know what must be found. We treated signals as optional metadata when they were the criteria for correctness.
Better systems don’t start by tuning similarity scores. They start by asking better questions about access. What information is required for this decision? Who has the authority to define truth here? How much context is necessary, and when does more become noise?
That change in questioning is where retrieval stops being guesswork and starts becoming design.
6. A Practical Retrieval-First Mental Model
The shift is simple, but uncomfortable: we filter first, then search.
For a long time, we ran similarity across everything and hoped the right documents would rise to the top. That’s backwards. You can’t rank what shouldn’t be eligible in the first place. Metadata isn’t decoration; it defines the boundaries of truth. Time, authority, status, and document type decide what is even allowed to be seen.
When someone asks, “What’s the current remote work policy?”, the system shouldn’t search every document that mentions remote work and then try to guess which one matters. It should first limit the space to active policy documents, owned by the right function, published after the last change. Only then does search make sense. The space is smaller, but the answers stop drifting.
After filtering, narrowing begins. This is where different signals finally complement each other instead of competing. Lexical cues anchor intent. Words like “exception,” “effective date,” or “commitment” are not themes; they’re structural hints. Semantic matching fills in the gaps when phrasing varies. Precision comes from structure. Flexibility comes from meaning. Both are necessary, but only after the scope is controlled.
The final step is context assembly, and this is where intent dictates shape. Different questions require different kinds of evidence. A policy question needs the rule, its effective date, and its authority. A timeline question needs a short sequence of decisions, not a pile of related discussion. A statement question needs the exact words, plus just enough surrounding context to interpret them correctly.
More context does not make answers better. It often makes them vaguer. If one document fully answers the question, that’s enough. Padding the context window with loosely related material just forces the model to average meaning instead of relying on evidence.
The sequence matters: filter to define validity, narrow to capture intent, assemble to support reasoning. Each step is a deliberate design choice that constrains what the model can see and, therefore, what it can generate.
When retrieval is designed this way, it stops feeling mechanical. It becomes a series of explicit judgments about access to knowledge. That’s when tuning gives way to clarity, and retrieval starts acting like architecture instead of configuration.
7. Chunking as an Implementation Detail
Once retrieval is right, chunking becomes boring. That isn’t dismissive. Boring is good. It means the hard decisions are already behind you.
We used to treat chunking like a philosophy. Now it’s just plumbing. When retrieval is designed with the right signals, sequencing, and intent awareness, chunking stops carrying architectural weight. It still matters, but it no longer decides whether the system works.
Pre-chunking is usually enough when documents are stable and queries are predictable. Policies, procedures, meeting notes, and structured internal docs don’t need to be reinterpreted on every request. Static segmentation gives consistency, speed, and simplicity. For most corpora, that’s sufficient.
Dynamic or post-retrieval chunking earns its cost only when variance forces it. Heterogeneous documents, shifting query intent, or questions that require different amounts of context from the same source make static boundaries brittle. In those cases, deferring chunking until after retrieval narrows the space allows the system to adapt the shape of context to the question being asked.
Mature systems don’t argue about this. They mix both approaches quietly. Some document types are pre-chunked because it’s cheap and effective. Others remain whole and are processed on demand. The choice is driven by document behavior and query intent, not ideology.
Chunking quality is never about size or overlap in isolation. It depends entirely on retrieval doing its job upstream. If the system retrieves the wrong documents, perfect chunking won’t save it. If it retrieves the right ones, chunking becomes a matter of how much to show, not what to show.
That’s when the debates stop. Chunking fades into the background, where implementation details belong. And when that happens, it’s usually a sign the system has finally moved on to harder and more valuable problems.
8. Conclusion: Retrieval Is the System
We spent a long time fixing the wrong things. We tuned chunk sizes, debated similarity scores, swapped models, and celebrated better metrics. None of it mattered as much as we thought, because the real failures were happening earlier, in silence.
Retrieval decides what the model is allowed to know. It defines the evidence, constrains the reasoning space, and quietly determines whether an answer can ever be correct. By the time the LLM runs, most outcomes are already locked in.
When retrieval is treated as a component, systems feel fragile. When it’s treated as architecture, things start to stabilize. Signals replace guesswork. Intent shapes context. Precision becomes intentional instead of accidental.
Chunking stops being a battleground. Models stop being blamed. The system stops producing answers that are “almost right” and starts producing answers that are defensible.
RAG doesn’t fail because models can’t reason. It fails because we didn’t design access to knowledge carefully enough. Retrieval isn’t a layer to tune. It isn’t a step to optimize. Retrieval is the system.